열린강의실
양자 알고리즘 개괄: 소인수분해와 양자화학


KEY SUMMARY
20세기 이후 자연과학과 정보과학은 서로의 언어를 빌려가며 빠르게 가까워졌습니다. 그 가장 극적인 만남 중 하나가 양자 컴퓨터입니다. 양자역학의 중첩과 얽힘을 직접 계산 자원으로 사용해 고전 컴퓨터로는 다루기 어려운 문제를 풀어내려는 시도입니다. 이 글에서는 그 흐름을 두 줄기로 따라가려고 합니다. 한 줄기는 쇼어의 소인수분해 알고리즘이고, 또 한 줄기는 분자와 물질의 에너지 준위를 계산하는 양자화학 알고리즘입니다.
겉으로 보면 이 둘은 거리가 멀어 보입니다. 하나는 정수론과 암호학의 문제이고, 다른 하나는 화학과 응집물리의 문제이기 때문입니다. 그러나 두 알고리즘의 핵심 엔진은 놀라울 만큼 닮아 있습니다. 마치 동전의 앞면과 뒷면처럼, 겉보기에는 서로 다른 문제처럼 보이지만 본질적으로는 같은 문제를 풀고 있습니다. 둘 다 양자 푸리에 변환(Quantum Fourier Transform, QFT)을 통해 어떤 함수에 숨겨진 위상 정보를 간섭으로 끄집어내는 같은 원리를 공유합니다. 쇼어가 정수론적 함수의 주기를 읽어낸다면, 양자화학에서 쓰는 양자 위상 추정(Quantum Phase Estimation, QPE)은 시간 진화 연산자의 고유 위상을 읽어냅니다. 이 글의 목표는 두 알고리즘을 따로 소개하는 것이 아니라, 이들이 사실은 한 동전의 양면이라는 점을 보여 드리는 것입니다.
특히 양자화학은 양자 컴퓨터의 가장 자연스러운 응용처로 일찍부터 주목받아 왔습니다. 1982년 파인만(R. Feynman)이 자연이 양자역학을 따른다면 자연을 시뮬레이션할 컴퓨터도 양자적이어야 한다고 제안한 이래, 분자의 기저 상태 에너지를 정확히 계산하는 일은 양자 컴퓨터의 킬러 응용으로 꼽혀 왔습니다. 1990년대 후반 아브람스(Abrams)와 로이드(Lloyd)가 QPE를 양자화학 문제에 적용한 이래, 아스푸루-구직(Aspuru-Guzik) 등의 연구를 거치면서 분자 시뮬레이션은 양자 알고리즘 연구의 중심 무대 중 하나가 되었습니다. 신소재 설계, 촉매 개발, 신약 후보 분자 탐색처럼 산업적 의미가 큰 문제들이 결국 해밀토니안의 가장 낮은 고윳값 찾기로 귀결되기 때문입니다.
이 글은 양자 컴퓨팅을 처음 접하는 학부 1~2학년 독자를 염두에 두고 썼습니다. 수식은 꼭 필요한 곳에만 사용하고, 가능하면 그림과 비유로 직관을 먼저 전달하려 노력했습니다.
양자 병렬성: 알고리즘이 다른 이유
알고리즘의 가장 큰 유용성은 반복된 일처리에 있습니다. 단순한 작업을 여러 번 순차적으로 수행해야 할 때 컴퓨터는 탁월한 도구가 됩니다. 만약 이 과정을 병렬 작업으로 나눌 수 있다면 여러 프로세서를 동원하여 속도를 한층 더 끌어올릴 수도 있습니다. 양자 알고리즘도 형태는 다르지만 이와 유사한 성질을 지닙니다. 다만 for나 while 문으로 독립적으로 하나씩 처리하는 대신, 여러 상태를 동시에 만들고 그 위에서 필요한 연산을 한 번에 수행한 다음, 원하는 답을 확률적으로 찾아가는 전략을 취합니다. 확률적으로 답을 구하기 때문에 정답이 나올 확률을 증폭시키는 간섭의 설계가 핵심이며, 이 과정에서 사용할 수 있는 기법이 다양하므로 서로 다른 조합의 양자 알고리즘이 제시됩니다.

그림 1. 고전 탐색과 양자 병렬성의 비유. 고전 컴퓨터(왼쪽)가 갈림길을 하나씩 시도해 보는 닌자라면, 양자 컴퓨터(오른쪽)는 분신술로 모든 경로를 동시에 탐색하는 닌자에 비유할 수 있습니다. 잘못된 경로의 분신들은 상쇄 간섭으로 사라지고, 올바른 경로의 분신만 보강 간섭으로 살아남아 측정 시점에 정답이 드러납니다.
여러 상태를 동시에 만드는 양자 병렬성을 인기 애니메이션 나루토에 비유해 설명해 보겠습니다. (그림 1.) (이는 이해를 돕기 위한 비유이므로 지나치게 엄밀하게 해석하지 않으시기 바랍니다.) 거대한 미로 같은 숲에서 전설의 두루마리를 찾아야 하는 임무가 주어졌다고 합시다. 일반적인 닌자(고전 컴퓨터)는 홀로 숲에 들어가 첫 갈림길을 선택합니다. 막다른 길이면 되돌아와 다음 길을 시도하며, 이 과정을 끝없이 반복합니다. 반면 나루토(양자 컴퓨터)는 숲 입구에서 다중 그림자 분신술!을 외쳐 수천 명의 분신을 만들고, 분신들은 모든 갈림길과 오솔길로 동시에 흩어져 탐색을 시작합니다. 그러나 두루마리를 찾지 못한 잘못된 경로의 분신들은 서로 부딪혀 연기처럼 사라지고(상쇄 간섭), 올바른 경로의 분신만 뚜렷하게 남아(보강 간섭) 측정이 이루어질 때 본체가 그 경로를 알게 됩니다. 며칠이 걸릴 임무를 몇 분 만에 끝내는 것, 곧 수많은 가능성을 동시에 더듬어 짧은 시간에 답을 찾아내는 힘을 양자 병렬성에 비유할 수 있습니다. 다만 모든 분기 결과를 한 번에 읽는 것은 불가능하며, 정답 성분만 증폭하도록 간섭을 설계하는 것이 양자 알고리즘 설계의 핵심입니다.
여러 상태를 동시에 만든다는 사실은 병렬 연산의 관점에서도 의미가 있지만, 메모리 관점에서 더 큰 함의를 가집니다. 예컨대 100큐비트 상태를 완전 시뮬레이션하려면 \(2^{100}\)개의 복소수 진폭을 저장해야 하며, 배정밀도 기준 각 진폭은 실수부와 허수부를 합쳐 16바이트가 필요합니다. 따라서 총 메모리 요구량은 \(16 \times 2^{100}\)바이트, 즉 약 2천만 요타바이트(1요타바이트 \(= 10^{24}\)바이트)에 이릅니다. 2025년 기준 전 세계 디지털 데이터 총량이 수백 제타바이트(1요타바이트 \(\approx 1{,}000\)제타바이트) 수준으로 추정되므로, 100큐비트의 정밀 시뮬레이션에는 인류가 보유한 모든 디지털 데이터를 합친 것보다 수억 배 큰 메모리가 필요한 셈입니다. 더구나 연산에 해당하는 행렬까지 별다른 구조 없이 통째로 저장하려면 필요한 공간은 그 제곱에 비례해 증가합니다. 결론적으로, 오류 정정을 거친 약 100개의 논리 큐비트만 확보되어도 고전 컴퓨터가 그 상태를 그대로 따라 하는 것은 사실상 불가능해집니다. 물론 특정 구조를 지닌 회로나 약하게 얽힌 상태 등은 텐서 네트워크(tensor network)나 양자 몬테카를로(quantum Monte Carlo) 같은 기법으로 고전적 시뮬레이션이 가능한 경우도 있지만, 일반적인 강하게 얽힌 상태에서는 이러한 우회도 통하지 않습니다. 한 가지 분명히 해 둘 점은, 이것이 양자 컴퓨터가 그 방대한 정보를 한 번에 효율적으로 읽어낼 수 있다는 의미는 아니라는 것입니다. 양자 컴퓨터의 진정한 힘은 이 천문학적인 계산 공간을 활용하여 특정 문제의 정답을 효과적으로 증폭하고 추출하는 데에 있습니다.
쇼어의 소인수분해 알고리즘
이제 가장 유명하고 역사적으로도 중요한 양자 알고리즘인 쇼어의 소인수분해 알고리즘을 살펴보겠습니다. 1994년 수학자 피터 쇼어(Peter Shor)가 제안한 이 알고리즘은 양자 컴퓨터가 고전 컴퓨터로는 다항 시간 안에 풀리지 않는 문제를 다항 시간에 풀어낼 수 있음을 처음으로 엄밀히 보여 준 사례로, 양자 컴퓨터에 대한 학계와 산업계의 관심을 결정적으로 끌어올린 사건이었습니다. 그 여파는 단순한 수학적 흥미에 그치지 않습니다. 오늘날 인터넷 뱅킹과 통신의 근간을 이루는 RSA와 같은 공개키 암호 시스템이 바로 소인수분해의 어려움 위에 서 있기 때문에, 쇼어 알고리즘의 등장은 언젠가 도래할 양자 컴퓨터 시대에 대비해 암호 체계 전체를 갈아엎어야 한다는 경각심을 세계적으로 불러일으켰습니다. 쇼어 알고리즘의 진짜 실용적 기여는 암호 해독 자체에 있다기보다, 그 위협을 미리 계량하여 양자내성암호(Post-Quantum Cryptography)로의 선제적 전환을 이끌어내고, 이후 등장한 수많은 양자 알고리즘(특히 다음 절에서 다룰 양자화학 알고리즘)의 모태가 된 데에 있습니다.
왜 소인수분해가 어려운가
소인수분해 문제는 주어진 정수를 소수들의 곱으로 분해하는 문제입니다. RSA 암호는 두 개의 큰 소수를 곱하는 것은 쉽지만, 그 결과값에서 원래의 두 소수를 역으로 찾아내는 것은 극도로 어렵다는 수학적 비대칭성에 기반합니다. 이 문제는 정답(인수)이 주어지면 곱셈으로 쉽게 검증할 수 있어 NP에 속하지만, NP-완전(NP-complete)으로는 알려져 있지 않은 독특한 위치에 있습니다. 소인수분해할 정수를 \(N\)이라 하고, 이 정수의 비트 수(이진법 자릿수)를 \(n=\lceil\log_2 N\rceil\)이라 합시다. 이 글에서 \(\log\)는 별도 표시가 없는 한 밑이 2인 로그(\(\log_2\))를 뜻합니다. 현재까지 알려진 가장 빠른 고전 알고리즘은 \[\exp\!\left(\Theta\left(n^{1/3}(\log n)^{2/3}\right)\right)\] 정도의 시간이 걸립니다. 이는 \(n\)에 대해 지수 시간보다는 빠르지만 다항 시간에는 미치지 못하는 준지수 시간(sub-exponential time) 복잡도입니다. 실제로 수백 자리의 정수를 분해하는 일은 현대 슈퍼컴퓨터로도 사실상 불가능에 가까운 일이고, 그 어려움이 곧 RSA 암호의 안전성을 떠받쳐 왔습니다. 예를 들어 현재 인터넷 뱅킹에 널리 쓰이는 RSA-2048(2048비트, 약 617자리 정수)을 고전 컴퓨터로 소인수분해하려면 수조 년 이상이 걸릴 것으로 추정됩니다.
쇼어 알고리즘은 이 문제에 대한 접근법을 근본적으로 바꾸었습니다. 가능한 후보들을 순차적으로 검증하는 대신, 양자 중첩으로 가능한 모든 후보의 정보를 하나의 양자 상태에 동시에 담은 뒤, QFT를 사용해 그 속에 숨은 주기를 효율적으로 끄집어냅니다. 그 결과 소인수분해의 양자 시간 복잡도는 \(O(n^3)=O((\log N)^3)\) 수준의 다항식이 됩니다. 즉 양자 컴퓨터에게 소인수분해는 BQP(Bounded-error Quantum Polynomial time, 양자 컴퓨터로 다항 시간 안에 높은 확률로 답을 구할 수 있는 문제의 부류)에 속하는 쉬운 문제가 됩니다. 실제로 약 2천만 개의 물리 큐비트를 갖춘 오류 정정 양자 컴퓨터라면 RSA-2048을 약 8시간 안에 소인수분해할 수 있을 것으로 추산됩니다. 고전 컴퓨터로는 수조 년이 걸리는 문제가 양자 컴퓨터에서는 하루도 채 걸리지 않는다는 뜻입니다.
더욱이 쇼어 알고리즘은 소인수분해뿐 아니라 이산 로그 문제(Discrete Logarithm Problem)도 다항 시간에 풀 수 있습니다. 이는 비트코인 등 가상화폐의 근간이 되는 타원곡선암호(ECC)를 비롯하여 TLS, SSH, 전자여권 등 현대 공개키 암호의 거의 전부가 하나의 양자 알고리즘에 의해 한꺼번에 흔들릴 수 있음을 의미합니다. 최근 구글 양자 AI 팀은 비트코인이 사용하는 256비트 타원곡선(secp256k1)의 이산 로그를 풀기 위해 약 1,200개의 논리 큐비트와 9천만 개의 Toffoli 게이트가 필요하며, 초전도 양자 컴퓨터 기준으로 50만 개 미만의 물리 큐비트로 약 9~23분이면 충분하다는 자원 추산을 발표했습니다. 아직 이 규모의 오류 정정 양자 컴퓨터는 존재하지 않지만, 이처럼 구체적인 수치가 나오기 시작했다는 점이 중요합니다. 덕분에 보안 업계는 막연한 미래의 위협이 아니라 정량적으로 가늠 가능한 일정표를 손에 쥐게 되었고, 양자내성암호(Post-Quantum Cryptography)로의 전환을 구체적으로 설계할 수 있게 되었습니다. 2024년 NIST가 양자내성암호 표준(FIPS 203, 204, 205)을 최종 발표한 것도 이러한 흐름의 일환으로, 쇼어 알고리즘의 파괴적 가능성이 실제로는 더 튼튼한 차세대 암호 체계를 앞당기는 건설적 추동력으로 작동하고 있는 셈입니다.
소인수분해를 주기 찾기로 바꾸기
쇼어 알고리즘의 핵심 아이디어는 소인수분해 문제를 어떤 함수의 주기를 찾는 문제로 환원하는 것입니다. 자세한 함수의 모양은 잠시 미루고, 우선 큰 그림부터 정리해 봅시다.
분해할 정수를 \(N\)이라 하고, \(N\)과 서로소인 정수 \(a\)(\(1 \lt a \lt N\))를 임의로 잡아 어떤 함수 \(f(x)\)를 만들었다고 합시다. \(f\)가 주기 \(r\)을 가진다고 할 때(즉 \(f(x+r)=f(x)\)), 적당한 조건이 만족되면 이 \(r\)로부터 \(N\)의 인수를 효율적으로 얻을 수 있다는 것이 정수론의 결과입니다. 따라서 \(r\)을 빠르게 구하기만 할 수 있다면 \(N\)을 빠르게 인수분해하기도 할 수 있게 됩니다. 이 환원의 마지막 다리는 유클리드 호제법(Euclidean algorithm)이며, 이는 두 정수 \(A, B\)의 최대공약수를 \(\gcd(A, B)=\gcd(B, A \bmod B)\)를 반복 적용해 매우 빠르게 구하는 고전 알고리즘입니다.
핵심은 주기를 찾는 일이 양자 컴퓨터가 특히 잘하는 일이라는 점에 있습니다. 고전 컴퓨터는 함숫값을 일일이 계산해 가며 반복 패턴을 찾아야 하지만, 양자 컴퓨터는 모든 입력값에 대한 함숫값을 중첩 상태로 한꺼번에 펼쳐 놓고, QFT라는 간섭 돋보기를 통과시키면 주기성 정보가 한 점에 모이게 됩니다. 이 통찰이 쇼어 알고리즘의 출발점입니다.
쇼어가 떠올린 환원의 구체적인 형태는 다음과 같습니다. 분해할 정수 \(N\)에 대해 \(\gcd(a, N)=1\)인 임의의 밑 \(a\)를 골라(만약 우연히 \(\gcd(a, N) \gt 1\)이라면 그 자체가 인수입니다)
\[ f(x)=a^x \bmod N \]이라는 함수를 정의합니다. \(x=0, 1, 2, \ldots\)에 대해 \(f(x)\)를 계산하면 어떤 양의 정수 \(r\)이 존재해 \(f(x+r)=f(x)\)가 되는데, 이 \(r\)이 주기입니다. 모듈러 연산처럼 가능한 값의 가짓수가 유한한 세계에서는 반복(주기)이 반드시 생기며, 그 반복은 단순한 되풀이를 넘어 \(N\)의 내부 구조(약수)에 대한 단서를 제공합니다.
주기를 알았다고 해서 곧장 인수가 나오는 것은 아닙니다. 보통 주기 \(r\)이 짝수이고, \(a^{r/2}\)를 \(N\)으로 나눈 나머지가 \(N-1\)이 아니면 성공합니다. 이 조건이 만족되면
\[ \gcd(a^{r/2}-1,\,N) \quad \text{또는} \quad \gcd(a^{r/2}+1,\,N) \]중 적어도 하나가 1도 \(N\)도 아닌 값을 주며, 그 값이 바로 \(N\)의 인수가 됩니다. 만약 조건이 맞지 않으면 다른 \(a\)를 골라 같은 과정을 반복하면 되고, 이 재시도 확률은 충분히 낮은 것으로 알려져 있습니다.
QFT가 주기를 끌어내는 방식
이제 양자 컴퓨터가 어떻게 주기 \(r\)을 효율적으로 찾는지 살펴봅시다. 알고리즘은 두 개의 레지스터(register, 큐비트들을 묶어 만든 양자 메모리)를 사용합니다. 첫 번째(입력) 레지스터는 \(n\)큐비트로 이루어져 \(0\)부터 \(Q-1\)(\(Q=2^n\), 보통 \(N^2 \le Q < 2N^2\))까지의 정수를 담고, 두 번째(출력) 레지스터는 \(f(x)\) 값을 담습니다. 한 가지 주의할 점이 있습니다. 앞 절에서 \(N\)의 비트 수를 \(n=\lceil\log_2 N\rceil\)로 정의했는데, 이 절에서 입력 레지스터 크기를 가리키는 \(n\)은 \(Q \approx N^2\)이 되도록 잡아 약 두 배 큰 값이 됩니다. 두 경우 모두 같은 문자 \(n\)을 쓰는 것은 관례이며, 최종 복잡도 \(O(n^3)\) 자체는 어느 정의를 따르든 \(O((\log N)^3)\)과 동등하므로 실질적인 결론에는 차이가 없습니다.
1단계: 균등 중첩 만들기.
모든 큐비트에 하다마드 게이트(\(|0\rangle \mapsto \frac{1}{\sqrt{2}}(|0\rangle+|1\rangle)\))를 적용해 첫 번째 레지스터를 \(0\)부터 \(Q-1\)까지 모든 정수가 같은 진폭으로 중첩된 상태 \[\frac{1}{\sqrt{Q}}\sum_{x=0}^{Q-1}|x\rangle|0\rangle\] 로 만듭니다. 이 상태 하나에 모든 입력이 들어 있는 셈입니다.
2단계: 모듈러 지수 함수 적용.
양자 알고리즘에서 오라클(oracle)이란 어떤 함숫값을 큐비트 상태에 적어 넣어 주는 양자 회로를 부르는 이름으로, 함수의 내부 구조를 자세히 들여다보지 않고 입력에 대응하는 출력만 가역적으로 계산해 주는 일종의 마법 상자라고 생각하면 됩니다. 이번 단계에서 사용할 가역적 오라클 \(U_f:|x\rangle|0\rangle \mapsto |x\rangle|f(x)\rangle\)를 한 번 적용하면 상태는 \[\frac{1}{\sqrt{Q}}\sum_{x=0}^{Q-1}|x\rangle|a^x \bmod N\rangle\] 이 됩니다. 두 레지스터가 얽혔으며, 입력 \(x\)와 출력 \(a^x \bmod N\)이 일대일로 짝지어진 거대한 표가 단 한 번의 양자 연산으로 만들어진 것입니다.
이 오라클을 효율적으로 구현하는 데에는 약간의 수학적 기교가 필요합니다. \(f(x)=a^x \bmod N\)의 지수는 \(x\)에 대해 선형이지만 함숫값은 지수적으로 자라기 때문에, 큰 \(x\)에 대해 직접 계산하면 시간이 많이 듭니다. 그러나 \(x\)를 이진수 \(x=\sum_k x_k 2^k\)로 쓰면 \[a^x \bmod N = \prod_k \left(a^{2^k} \bmod N\right)^{x_k}\] 이 되어, 상수 \(c_k = a^{2^k} \bmod N\)들을 고전적으로 미리 계산해 둘 수 있습니다(\(k\)번의 반복 제곱). 그다음 회로에서는 비트 \(x_k=1\)일 때만 결과 레지스터에 \(c_k\)를 곱하는 제어-모듈러 곱셈을 수행하면 됩니다.
이 반복 제곱법이 왜 결정적인지 잠시 짚어 봅시다. \(a\)를 \(x\)번 곱하는 순진한 방법은 \(x\)가 \(N\)에 가까워지면 약 \(2^n\)번의 곱셈을 요구하여 \(n\)에 대해 지수적입니다. 반면 위의 분해는 \(a, a^2, a^4, \ldots, a^{2^{n-1}}\) 단 \(n\)개의 상수만 미리 준비하면 되고, 그 뒤 어떤 \(x\)에 대해서든 \(a^x \bmod N\)을 최대 \(n\)번의 모듈러 곱셈으로 얻을 수 있어 비용이 \(n\)에 대해 다항입니다. 이 다항 시간짜리 회로 안에서 \(Q=2^n\)개의 입력에 대한 함숫값이 동시에 중첩으로 만들어지므로, 다항 비용으로 지수적 양의 정보를 펼친다는 구조가 성립합니다. 바로 이 점이 쇼어 알고리즘의 지수적 속도 향상을 떠받치는 한 축입니다.
3단계: 출력 레지스터 측정으로 주기 구조 노출.
두 번째 레지스터를 측정해 어떤 값 \(y_0=a^{x_0}\bmod N\)을 얻었다고 합시다. 그러면 첫 번째 레지스터는 \(y_0\)를 만들어내는 모든 \(x\)들의 중첩으로 붕괴합니다. \(f\)가 주기 \(r\)을 가지므로 살아남는 \(x\)들은 \(x_0, x_0+r, x_0+2r, \ldots\)처럼 등간격 \(r\)로 늘어서며, 첫 번째 레지스터는
\[ \frac{1}{\sqrt{K}}\sum_{k=0}^{K-1}\ket{x_0+kr},\qquad K\approx Q/r \]가 됩니다. 즉 입력 레지스터에 주기 \(r\)의 주기적인 진폭 분포가 새겨집니다. 함숫값 자체는 측정으로 사라졌지만, 그 주기성은 여전히 첫 번째 레지스터 안에 등간격 점열의 형태로 남아 있는 것입니다.
4단계: QFT로 주기 읽어내기.
주기적인 신호에 푸리에 변환을 가하면 주기의 역수 위치에 뾰족한 봉우리가 생긴다는 것은 신호 처리에서 익숙한 사실입니다. 양자판 푸리에 변환인 QFT는 \[ \ket{x}\;\mapsto\; \frac{1}{\sqrt{Q}}\sum_{s=0}^{Q-1} e^{2\pi i\,xs/Q}\ket{s} \] 로 정의됩니다. 이를 3단계에서 얻은 주기적 중첩 상태에 적용해 봅시다. QFT는 선형 연산이므로 합 안의 각 기저 상태 \(\ket{x_0+kr}\)에 따로따로 적용한 뒤 결과를 모으면 됩니다: \[ \frac{1}{\sqrt{K}}\sum_{k=0}^{K-1}\ket{x_0+kr} \;\xrightarrow{\;\text{QFT}\;}\; \sum_{s=0}^{Q-1} \underbrace{\frac{1}{\sqrt{KQ}}\!\left(\sum_{k=0}^{K-1} e^{2\pi i\,(x_0+kr)\,s/Q}\right)}_{\text{각 } s\text{에 대한 진폭}~\alpha_{s}} \ket{s}. \] 괄호 안의 합을 정리해 봅시다. 지수에서 \(x_0\) 부분은 \(k\)와 무관한 공통 위상이므로 밖으로 빠지고, 남는 부분은 공비 \(e^{2\pi i\, rs/Q}\)를 가지는 등비급수가 됩니다. 등비급수 합 공식을 적용하고 절댓값을 취하면 결국 \(\ket{s}\)가 측정될 진폭의 크기는 \[ |\alpha_s| \;=\; \frac{1}{\sqrt{KQ}}\left|\frac{\sin(\pi K\,rs/Q)}{\sin(\pi\, rs/Q)}\right| \] 의 디리클레 커널(Dirichlet kernel) 꼴을 갖습니다. 이 식이 갑자기 복잡해 보일 수 있지만 모양은 날카로운 봉우리(좁은 sinc 형태)와 닮아 있습니다.
이 식이 주는 직관은 단순합니다. 합 속의 각 항은 단위 원 위의 화살표(복소수 위상)인데, 공비 \(e^{2\pi i\, rs/Q}\)가 1에 가까우면 모든 화살표가 거의 같은 방향을 가리켜 더해질 때 길게 자라고(보강 간섭), 공비가 단위 원 위에 고르게 퍼지면 화살표들이 서로 상쇄되어 합이 거의 0이 됩니다(상쇄 간섭). 공비가 1에 가깝다는 조건은 \(rs/Q\)가 어떤 정수 \(t\)에 가깝다는 것, 즉 \(s/Q \approx t/r\)이라는 것과 같습니다. 결과적으로 측정값 \(s\)는 \(|s/Q-t/r| \lt 1/(2r^2)\)를 만족하는 값들로 높은 확률로 모이게 됩니다. 이 주기적 중첩 → 뾰족한 봉우리 변환을 시각적으로 확인할 수 있게 그림 2에 정리해 두었습니다.
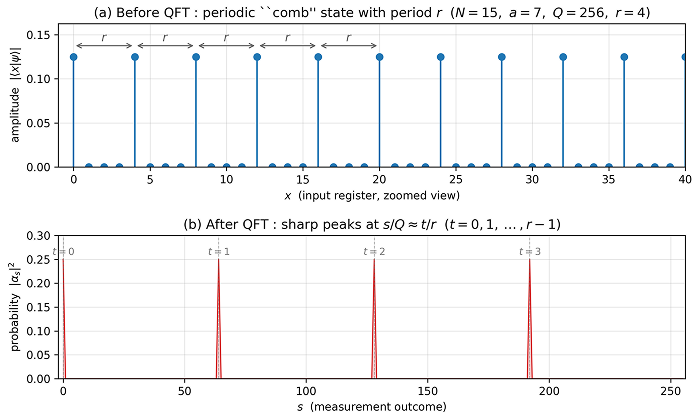
그림 2. 쇼어 알고리즘의 핵심 직관을 \(N=15\), \(a=7\) 예제(\(f(x)=7^x \bmod 15\))로 시각화했습니다. 이 함수의 실제 주기는 \(r=4\)이며(\(f(0)=1,\ f(1)=7,\ f(2)=4,\ f(3)=13,\ f(4)=1, \ldots\)로 4칸마다 1이 반복됨), 입력 레지스터 크기는 \(Q=2^8=256\)입니다. (a) 3단계 직후 첫 번째 레지스터의 진폭 분포를 처음 40칸까지 확대해 본 모습으로, \(x=0, 4, 8, 12, \ldots\) 위치에만 동일한 진폭 \(1/\sqrt{K}\)가 서고 나머지에서는 0입니다. 즉 주기 \(r=4\)가 등간격 점열로 눈에 보이게 드러납니다. (b) 여기에 QFT를 적용한 뒤 측정 확률 \(|\alpha_s|^2\)의 분포로, 이론적으로 봉우리는 \(s = tQ/r = t \times 64\) 위치, 즉 \(s=0, 64, 128, 192\)(\(t=0,1,2,3\))에 서야 합니다. 그림에서도 정확히 이 네 지점에 폭이 약 \(1/K\) 정도로 좁고 날카로운 sinc 형태의 봉우리가 솟아 있는 것을 확인할 수 있으며, 측정값을 연분수 전개로 해석하면 분모 \(r=4\)가 복원됩니다.
5단계: 연분수 전개로 r 복원.
측정값 \(s/Q\)는 정확히 \(t/r\)이 아니라 그에 매우 가까운 유리수입니다. 연분수 전개는 실수의 정수 부분을 떼고 남은 부분의 역수를 취하는 과정을 반복하여 분수의 좋은 근사를 차례로 얻어내는 고전적인 기법인데, \(s/Q\)를 연분수로 전개해 분모가 작은 근사 분수들을 차례로 후보로 삼으면 그 안에서 \(r\)을 빠르게 복원할 수 있습니다.
QFT는 \(n=\log_2 Q\)에 대해 \(O(n^2)\)개의 게이트로 구현할 수 있고, 모듈러 지수 연산까지 포함한 전체 양자 시간 복잡도는 \(O(n^3)\) 수준입니다.
QFT의 빠르기도 잠시 짚어 둘 만합니다. 같은 \(Q=2^n\)개의 데이터에 대해 고전 컴퓨터에서 가장 빠르다고 알려진 빠른 푸리에 변환(Fast Fourier Transform, FFT)조차 \(O(Q\log Q) = O(n\,2^n)\) 시간이 걸려 입력 크기 \(n\)에 지수적입니다. 반면 QFT는 같은 변환을 \(O(n^2)\)개의 게이트, 즉 \(n\)에 다항으로 끝냅니다. 비결은 회로 구조 자체에 있습니다. QFT는 큐비트마다 하다마드 게이트를 한 번 적용하고, 다른 큐비트들과의 사이에서 제어-위상 회전 게이트를 차례로 엮는 식으로 만들어집니다. 이러한 각 큐비트가 다른 모든 큐비트와 한 번씩 짝지어 위상 회전을 주고받는 이중 루프 구조 덕분에 게이트 수가 \(n\)의 제곱으로만 자라는 것입니다. 앞서 본 모듈러 지수의 반복 제곱법과 마찬가지로, QFT 역시 다항 비용으로 지수적 크기의 변환을 수행하는 구조 위에 서 있는 셈입니다.
결국 중첩으로 모든 입력 펼치기 → 주기 구조를 등간격 점열로 노출 → QFT로 주파수 검출이라는 세 단계가 쇼어 알고리즘의 본질이며, 놀랍게도 이 패턴은 다음 절의 양자화학 알고리즘에서도 거의 그대로 반복됩니다.
쇼어 알고리즘에서 양자화학으로
쇼어가 정수론적 함수의 주기를 찾는 데 양자 컴퓨터를 썼다면, 양자화학에서는 같은 도구로 분자의 에너지를 찾습니다. 양자화학(quantum chemistry)은 이름 그대로 양자역학의 원리에 따라 원자와 분자의 성질을 계산하는 분야인데, 그 중심에는 분자의 전자 구조(electronic structure) 문제가 있습니다. 분자의 형태와 반응성, 스펙트럼, 결합 에너지 같은 화학적 성질은 대부분 원자핵들이 만드는 전기 퍼텐셜 속에서 전자들이 어떻게 배열되는가로 결정되기 때문입니다. 형식적으로는 분자나 고체의 전자 해밀토니안 \(H\)의 가장 낮은 고윳값(기저 상태 에너지)과 그에 대응하는 고유 상태(전자 파동함수)를 구하는 문제로 요약됩니다. 분자의 전자 수가 조금만 늘어도 다전자 파동함수의 자유도는 지수적으로 폭발하므로, 풀어낼 수 있는 분자의 크기에 고전 계산은 본질적인 한계를 가집니다. 특히 강한 상관관계를 가진 전이금속 촉매나 광합성 반응 중심 같은 계는, 바닥 상태 하나를 기술하는 데에도 서로 비슷한 에너지를 가진 수많은 전자 배치가 함께 얽혀 기여해야 합니다. 한두 개의 지배적인 전자 배치로 정리되는 일반 분자와 달리, 이런 계는 기저 상태를 정확히 표현하는 데 지수적으로 많은 기저 상태가 필요하고, 고전 계산에서 쓰는 평균장 근사나 몇 차 보정만으로는 그 구조를 포착하기 어렵습니다. 화학자들이 오랜 세월 발전시킨 하트리–폭(Hartree–Fock)이나 결합 클러스터(coupled cluster) 같은 방법은 평균장과 영리한 다체 보정의 조합으로 이 한계를 밀어붙여 왔지만, 이러한 강상관 계 앞에서는 여전히 한계를 보입니다.
이 지점에서 양자 컴퓨터의 자연스러운 역할이 등장합니다. 양자 상태를 양자 상태로 직접 표현하므로 다전자 파동함수의 차원 폭발을 피할 수 있고, 시간 진화 \(U(t)=e^{-iHt}\)를 다항 시간에 시뮬레이션할 수 있는 알고리즘들이 알려져 있습니다. 그리고 이 시간 진화에서 에너지 정보를 끄집어내는 주된 도구가 바로 양자 위상 추정(QPE)입니다.
다만 이 이야기를 실제 양자 회로로 옮기기 전에 거쳐야 할 준비 단계가 하나 있습니다. 큐비트가 이해하는 언어는 스핀 1/2 계의 파울리 연산자 \(X, Y, Z\)로 된 조합뿐인데, 전자 해밀토니안은 본래 페르미온 생성·소멸 연산자로 쓰여 있어 모양이 다르기 때문입니다. 그래서 양자화학을 양자 회로에 올리기 위해서는 페르미온 연산자를 큐비트 연산자로 바꿔 주는 번역 절차가 필요합니다. 조던–위그너(Jordan–Wigner) 변환이 가장 고전적이면서도 널리 쓰이는 방법이며, 이 밖에도 브라비–키타에프(Bravyi–Kitaev) 변환 등 목적에 따라 여러 변환이 사용됩니다. 변환을 거친 뒤의 해밀토니안은 결국 \[ H = \sum_{\alpha} h_\alpha\, P_\alpha,\qquad P_\alpha \in \{I,X,Y,Z\}^{\otimes m} \] 과 같이 여러 큐비트에 걸친 파울리 연산자의 곱(파울리 스트링)들의 선형 결합으로 표현됩니다. 이 형태가 되면 각 항 \(e^{-i h_\alpha P_\alpha \,\Delta t}\)를 기본 게이트들의 조합으로 구현할 수 있고, 트로터 분해(Trotter decomposition) 등을 통해 전체 시간 진화 \(e^{-iHt}\)를 근사적으로 쌓아 올릴 수 있게 됩니다. 덧붙여 둘 점은, 이러한 변환은 양자화학에 국한된 이야기가 아니라는 사실입니다. 허버드 모형이나 자기 모형 같은 응집물리의 양자 다체 문제, 격자 게이지 이론 등 페르미온이나 하드코어 보손 등을 포함하는 어떤 양자 다체 해밀토니안이든 양자 회로에서 다루기 위해서는 비슷한 방식으로 파울리 스트링의 선형 결합 형태로 옮겨지며, QPE를 비롯한 양자 알고리즘들이 다양한 물리·화학 문제에 공통의 틀로 적용될 수 있는 기반이 됩니다.
쇼어와 QPE를 잇는 다리: 주기 대 위상
쇼어가 찾아낸 주기적 중첩 구조를 한 번 더 떠올려 봅시다. 주기 \(r\)인 함수 \(f(x)=a^x \bmod N\)은 입력 \(x\)가 한 칸 진행할 때 어떤 패턴이 한 번 반복되는가를 묻는 함수입니다. 이 그림을 양자화학으로 옮기면, 입력은 시간 \(t\)이고, 패턴은 시간 진화 연산자의 위상이 됩니다. 해밀토니안 \(H\)의 고유 상태 \(\ket{\psi_j}\)는
\[ U(t)\ket{\psi_j} = e^{-iE_j t}\ket{\psi_j} \]를 만족하므로, 시간 \(t\)가 한 단위 진행할 때마다 위상은 일정한 비율로 회전합니다. 임의의 입력 상태 \(\ket{\Psi}=\sum_j c_j\ket{\psi_j}\)를 고려하면, 시간에 따른 자기상관 함수
\[ g(t) \;=\; \langle \Psi | U(t) | \Psi \rangle \;=\; \sum_j |c_j|^2 \, e^{-iE_j t} \]는 여러 주파수 \(E_j\)를 가진 진동들의 합입니다. 즉 쇼어가 다루는 주기 함수와 QPE가 다루는 자기상관 함수는 본질적으로 같은 계열의 함수이며, 둘 다 푸리에 변환의 봉우리 위치를 읽음으로써 핵심 정보(주기 \(r\) 또는 에너지 \(E_j\))를 얻을 수 있습니다.
이 점에서 QPE는 쇼어 알고리즘의 자연스러운 일반화입니다. 정수론적 주기에서 물리적 위상으로 대상이 바뀔 뿐, 간섭으로 위상을 증폭해 읽는다는 철학은 동일합니다. 두 알고리즘의 닮음과 차이는 표 1에 한눈에 정리해 두었습니다.
표 1: 쇼어 알고리즘과 QPE 비교. 두 알고리즘은 입력과 응용 분야가 전혀 다르지만, 함수의 위상 구조를 푸리에 변환으로 끌어낸다는 공통 엔진을 공유합니다. 동전의 앞면과 뒷면이 모양은 달라도 같은 동전이듯, 이 두 알고리즘도 겉보기는 달라도 속은 같습니다.
| 쇼어 알고리즘 | 양자 위상 추정 (QPE) | |
|---|---|---|
| 입력 | 정수 \(N\), 임의의 밑 \(a\) | 해밀토니안 \(H\), 시간 \(t\), 입력 상태 \(\ket{\Psi}\) |
| 대상 함수 | \(f(x) = a^x \bmod N\) | \(g(t) = \sum_j |c_j|^2 e^{-iE_j t}\) |
| 끌어낼 정보 | 주기 \(r\) (정수론적) | 고유 위상 \(\phi_j \to E_j\) (물리적) |
| 양자 엔진 | QFT | (역) QFT |
| 사후 처리 | 연분수 전개로 \(r\) 복원 | 반복 측정으로 통계 누적 |
| 시간 복잡도 | \(O(n^3)\), \(n=\log_2 N\) | 다항 시간 \(\times\,1/\Delta E\) |
| 대표 응용 | 암호 체계 안전성 평가, 양자내성암호 전환 | 분자 기저 상태 에너지 |
표 1의 양자 엔진 줄에서 한 가지 짚어둘 점이 있습니다. 쇼어 알고리즘과 QPE는 관례적으로 각각 QFT와 역 QFT를 쓰는 것으로 소개되는데, 둘은 사실상 동일한 구조의 회로이며 서로의 켤레 전치(복소수 위상의 부호 반전)일 뿐입니다. 어느 쪽을 정방향으로 부르느냐는 입력 상태를 어떻게 정의하느냐에 따른 관습에 가깝습니다. 쇼어는 등간격 점열 상태를 주파수 쪽으로 펼치기 위해 QFT를 쓴다고 기술하고, QPE는 시간 간격으로 샘플링된 위상을 이진 표현의 봉우리로 옮긴다는 관점에서 역 QFT를 쓴다고 기술합니다. 두 알고리즘이 근본적으로 같은 도구를 쓴다는 사실은 바뀌지 않습니다.
쇼어와 QPE가 같은 도구를 쓴다는 점은 두 알고리즘이 빠른 이유까지 공유한다는 뜻이기도 합니다. 쇼어 알고리즘에서 보았듯, QFT는 \(Q=2^n\)차원의 푸리에 변환을 단 \(O(n^2)\)개의 게이트로 수행하여, 같은 일을 \(O(n\,2^n)\) 시간에 처리하는 고전 FFT를 지수적으로 앞섭니다. 정확히 같은 가속이 QPE에서도 일어납니다. 보조 레지스터에 새겨진 위상 패턴 \(\{e^{2\pi i\phi 2^k}\}\)를 봉우리로 읽어내는 마지막 단계가 바로 (역) QFT이기 때문입니다. 만약 이 자리에 고전 FFT를 끼워 넣어야 했다면 QPE의 실용성은 사라졌을 것입니다. 결국 쇼어 알고리즘이 고전적으로 어려운 정수론 문제를 다항 시간에 풀 수 있는 이유와 QPE가 분자 에너지를 효율적으로 추정할 수 있는 이유는 똑같이 QFT의 빠르기에서 나옵니다. 동전의 양면이 같은 동전인 것은 같은 철학(간섭으로 위상을 읽는다)뿐 아니라 같은 엔진(QFT)을 공유하기 때문입니다.
QPE의 작동 원리
QPE는 다음과 같이 작동합니다. 두 개의 레지스터를 준비하고 보조 레지스터를 \(n\)큐비트의 균등 중첩으로 만든 뒤, 각 \(\ket{k}\)를 제어 비트로 삼아 시스템 레지스터에 \(U^{2^k}\)를 적용합니다. 그러면 위상 되먹임(phase kickback)에 의해 다음 얽힘 상태가 만들어집니다. \[ \frac{1}{\sqrt{2^n}}\sum_{k=0}^{2^n-1}\ket{k}\otimes \big(U^{2^k}\ket{\Psi}\big) \;=\; \sum_j c_j\!\left(\frac{1}{\sqrt{2^n}}\sum_{k=0}^{2^n-1}e^{2\pi i\,\phi_j 2^k}\ket{k}\right)\!\otimes \ket{\psi_j}, \] 여기서 \(\phi_j = E_j t / (2\pi)\)입니다. 이 회로 구조를 그림 3에 나타냈습니다. 보조 레지스터에는 각 고유 성분 \(j\)에 대해 위상 패턴 \(\{e^{2\pi i\phi_j 2^k}\}\)가 새겨져 있고, 이 패턴은 정확히 주파수 \(\phi_j\)의 진동을 다양한 시간 간격으로 샘플링한 결과에 해당합니다. 이 시점에서 보조 레지스터는 \(0\)부터 \(2^n-1\)까지 모든 비트열 \(\ket{k}\)가 거의 같은 크기의 진폭을 나누어 가진, 정보가 눈에 보이지 않는 상태입니다. 에너지에 대한 정보는 진폭의 크기가 아니라 위상에만 새겨져 있기 때문입니다.
여기에 역 QFT를 적용하는 것이 결정적인 한 수입니다. 역 QFT는 바로 앞 절에서 쇼어 알고리즘이 썼던 바로 그 간섭 장치와 같은 도구로, 각 기저 상태 \(\ket{s}\)의 새 진폭을 원래 진폭들을 특정 위상으로 모두 더한 합으로 바꿔 줍니다. \(s\)가 \(\phi_j\)의 이진 근사 \(s_j\)에 가까우면 \(j\)번째 성분에서 온 위상들이 정렬되어 보강 간섭으로 진폭이 크게 자라고, 멀면 위상들이 서로 엇갈려 상쇄 간섭으로 거의 0이 됩니다. 그 결과 전체 상태는 다음과 같이 정리됩니다: \[ \xrightarrow{\;\text{역 QFT}\;} \sum_j c_j \,\ket{\tilde\phi_j}_{\rm anc} \otimes \ket{\psi_j}_{\rm sys}. \] 여기서 \(\ket{\tilde\phi_j}_{\rm anc}\)는 \(\phi_j\)의 이진 근사 \(s_j/2^n \approx \phi_j\) 근처로 확률이 몰린 보조 레지스터 상태를 뜻합니다. 이 식이 QPE의 핵심 결과이자, 에너지가 보조 레지스터에 쓰여진다는 표현의 정확한 의미입니다. 보조 큐비트에 에너지의 숫자가 직접 기계적으로 기록된 것이 아니라, 수많은 비트열 \(\ket{s}\) 가운데 \(\phi_j\)에 해당하는 비트열에만 의미 있는 확률이 몰리도록 간섭이 설계되어 있다는 뜻입니다. 주목할 점은 이 몰림 현상이 각 고유 성분 \(\ket{\psi_j}\)와 짝지어 일어난다는 사실입니다. 즉 위 식은 고윳값 비트열 \(\ket{\tilde\phi_j}\)와 고유 상태 \(\ket{\psi_j}\)가 일대일로 얽힌 구조를 가지며, 바로 이 얽힘이 뒤에서 볼 측정 후 시스템 상태 생존의 비결이 됩니다.
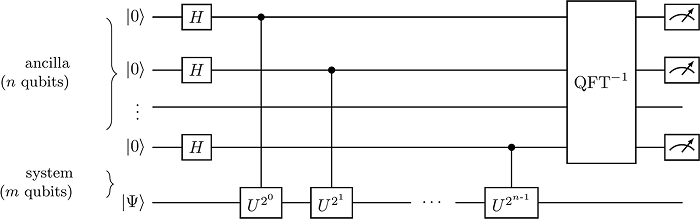
그림 3. 양자 위상 추정(QPE) 회로. 왼쪽 \(n\)개의 보조(ancilla) 큐비트는 모두 하다마드 게이트(\(H\))로 균등 중첩에 놓이고, 각 큐비트가 시스템 레지스터(\(m\)큐비트)에 \(U^{2^k}\)를 제어 적용합니다. 위상 되먹임으로 보조 레지스터에 위상 패턴 \(e^{2\pi i\phi\cdot 2^k}\)가 새겨지고, 마지막에 역 QFT(\(\mathrm{QFT}^{-1}\))가 이 패턴을 \(\phi\)의 이진 표현에 해당하는 봉우리로 변환하여 측정으로 읽어 냅니다.
이제 어떻게 에너지를 읽어내는지 살펴봅시다. 핵심은 측정의 대상이 보조 레지스터뿐이라는 점입니다. 보조 큐비트들을 0/1 기저(즉 각 큐비트가 \(\ket{0}\)인지 \(\ket{1}\)인지를 직접 묻는 표준적인 측정)로 측정하면, 0과 1로 이루어진 길이 \(n\)의 비트열 \(s\) 하나가 메모리에 기록됩니다. 이 비트열을 이진수로 읽고 \(2^n\)으로 나누면 \(s/2^n \approx \phi_j\)가 되어 위상 추정값을 얻고, \(\phi_j = E_j t/(2\pi)\) 관계로부터 에너지 \(E_j\)를 복원합니다. 어떤 \(j\)가 측정될지는 확률적이며, 그 확률은 초기 가중치 \(|c_j|^2\)와 위상 근사 오차에 의해 결정됩니다. 즉 한 번의 실행은 고유 에너지들 \(\{E_j\}\) 중 하나를 가중치 \(|c_j|^2\)의 분포에서 샘플링하는 것에 해당하고, 같은 회로를 여러 번 반복해 통계를 모으면 에너지 분포 전체를 가늠할 수 있습니다.
기저 에너지를 얻는 실제 절차는 가장 자주 나오는 값을 고르는 것이 아니라, 가장 낮은 에너지가 한 번이라도 나오기를 기다리는 것에 가깝습니다. 초기 상태가 \(\ket{\Psi_0}=\sum_j c_j \ket{\psi_j}\)로 전개될 때 측정으로 \(E_j\)가 나올 확률이 \(|c_j|^2\)이므로, 기저 상태의 가중치 \(|c_0|^2\)가 다른 어떤 \(|c_j|^2\)보다 반드시 큰 것은 아닙니다. 변분적으로 잘 준비한 시도 파동함수도 \(|c_0|^2\)가 다른 들뜬 상태들의 가중치보다 작은 경우가 흔합니다. 그래서 실제 알고리즘에서는 QPE를 여러 번 반복하면서 그때그때 보조 레지스터에서 읽어낸 에너지 추정값들을 모아 두고, 그 가운데 가장 낮은 값을 기저 에너지의 후보로 채택합니다.
이 기다림에서 결정적인 양은 \(|c_0|^2\)의 크기 자체가 아니라 스케일링입니다. \(|c_0|^2\)가 큐비트 수 \(n\)이나 분자 크기에 대해 \(1/\mathrm{poly}(n)\) 정도(즉 다항적으로만 작아짐) 머무른다면, 평균적으로 \(1/|c_0|^2 \sim \mathrm{poly}(n)\)번의 반복 안에 \(E_0\)를 한 번은 관측할 수 있어 알고리즘이 다항 시간에 끝납니다. 반면 \(|c_0|^2\)가 \(n\)에 대해 \(1/2^n\)처럼 지수적으로 작아진다면 \(E_0\)를 한 번 보는 데 지수적으로 오랜 시간을 기다려야 하므로, QPE는 사실상 작동하지 못합니다. 이것이 다음 절에서 살펴볼 좋은 초기 상태 준비가 단순한 최적화 기법이 아니라 알고리즘의 다항 시간 보장을 좌우하는 본질적 요건인 이유입니다.
앞에서 짚어 둔 얽힘 구조가 이 자리에서 결정적 역할을 합니다. 측정 직전의 전체 상태 \(\sum_j c_j \ket{\tilde\phi_j}_{\rm anc} \otimes \ket{\psi_j}_{\rm sys}\)는 각 보조 레지스터 상태 \(\ket{\tilde\phi_j}\)가 시스템 고유 상태 \(\ket{\psi_j}\)와 일대일로 짝지어져 얽혀 있는 형태입니다. 여기서 우리는 보조 레지스터만 측정하므로, 한쪽만 들여다보는 셈입니다. 양자역학의 측정 공준에 따라 보조 레지스터에서 어떤 비트열 \(s_j\)가 관측되는 순간 전체 얽힘은 그 비트열에 대응하는 한 항으로 사영되는데, 시스템 레지스터는 애초에 \(\ket{\tilde\phi_j}\)와 짝지어져 있던 \(\ket{\psi_j}\)만 골라져 살아남게 됩니다. 다시 말해, 보조 쪽에서 \(\phi_j\)에 해당하는 비트열을 보았다는 사실 하나만으로, 시스템 쪽에서는 자동으로 그에 대응하는 고유 상태 \(\ket{\psi_j}\)가 선택됩니다. 측정으로 사라지는 것은 보조 레지스터가 가지고 있던 여러 비트열 위의 중첩이지, 시스템 레지스터의 양자 상태 자체가 아닙니다. 결과적으로 한 번의 QPE 실행으로 우리는 두 가지를 동시에 얻습니다. 메모리에 기록된 비트열 \(s_j\)로부터 고전 정보 형태의 에너지 \(E_j\)를, 그리고 시스템 레지스터에는 그 에너지에 대응하는 양자 상태 \(\ket{\psi_j}\)를 함께 손에 쥐게 됩니다. 이것이 고윳값과 고유 상태를 동시에 얻는다는 말의 정확한 의미이며, 얽힘이 없었다면 성립하지 않을 일입니다.
이 점은 실용적으로 매우 중요합니다. 시스템 상태가 살아 있으므로, 그 상태를 그대로 다음 양자 회로의 입력으로 넘겨 다른 관측량(예: 쌍극자 모멘트, 전자 밀도, 다른 연산자의 기댓값)을 측정하거나, 시간 진화를 더 진행시켜 동역학을 들여다보거나, 에너지가 정렬된 이 상태에서 새로운 화학 반응 경로를 시뮬레이션할 수도 있습니다. QPE는 단순히 숫자 하나를 읽는 측정이 아니라, 에너지가 라벨된 양자 상태를 동시에 준비하는 절차로 이해하는 편이 정확합니다. 쇼어 알고리즘에서 측정값 \(s\)로부터 주기 \(r\)을 복원하면서 동시에 양자 회로가 그 다음 단계로 넘어갈 수 있었던 것과, 본질적으로 같은 구조입니다.
QPE를 쓸 때 주의할 두 가지
QPE의 실전에서는 두 가지를 신중히 고려해야 합니다.
첫째, 분해능을 정확히 이해해야 합니다.
위상 추정의 해상도는 얼마나 오래, 얼마나 세밀하게 위상을 관찰하느냐에 의해 결정됩니다. 보조 레지스터가 \(n\)큐비트이면 위상 \(\phi\)는 약 \(1/2^n\) 간격으로 구분되고, 에너지 분해능은 \[ \Delta E \;\approx\; \frac{2\pi}{\tau\, 2^n} \] 정도가 됩니다. 여기서 \(\tau\)는 기본 시간 스텝(\(U=e^{-iH\tau}\))이며, 회로에서 \(U^{2^k}\)를 누적해 쓰므로 최대 유효 진화 시간은 \(t_{\max}\approx 2^{n-1}\tau\)입니다. 결국 \(\Delta E = \Theta(1/t_{\max})\) 수준이며, 이는 고전 신호처리의 관측 시간을 늘릴수록 주파수 분해능이 좋아진다는 사실과 같은 원리입니다. 한편 유한한 \(n\)으로 구현된 역 QFT는 이상적인 델타 함수가 아니라 격자 위에 퍼진 sinc 형태의 봉우리로 결과를 내며, \(n\)이 커질수록 봉우리가 더 날카로워지고 격자도 촘촘해져 추정이 정밀해집니다.
쇼어 알고리즘과 QPE가 같은 동전의 양면이었던 것처럼, 이 분해능 관계식에도 흥미로운 숨은 동전이 있습니다. 위에서 본 분해능 관계식은 형태를 정리하면 \(\Delta E \cdot t_{\max} \sim 2\pi\)가 되는데, 이는 양자역학의 에너지-시간 불확정성 관계 \(\Delta E \cdot \Delta t \gtrsim \hbar\)와 형식이 닮아 있습니다. 물론 QPE의 분해능 논의는 이산 푸리에 변환의 수치적 성질에서 나온 것이고, 불확정성 원리는 파동함수의 물리적 성질에서 나온 것이므로 두 결과의 출처는 서로 다릅니다. 그러나 어떤 신호의 주파수(또는 에너지)를 얼마나 정밀하게 알려면 얼마나 오래 지켜봐야 하는가라는 질문은 고전 신호처리든 양자역학이든 같은 답을 주며, QPE는 그 공통된 원리를 양자 회로 위에서 구현한 셈입니다. 쇼어와 QPE가 간섭으로 위상을 읽는다는 철학을 공유하듯, QPE의 분해능 한계와 에너지-시간 불확정성도 유한한 관측 시간이 주파수 분해능을 제한한다는 같은 원리의 서로 다른 얼굴이라 할 수 있습니다.
둘째, QPE는 정보를 창조하지 않습니다.
초기 상태 \(\ket{\Psi_0} = \sum_j c_j \ket{\psi_j}\)가 이미 담고 있는 고유 성분만 확률적으로 드러낼 뿐이며, 특정 고윳값 \(E_k\)가 측정될 확률은 \(|c_k|^2\)에 비례합니다. 따라서 기저 에너지를 안정적으로 얻고 싶다면 애초에 \(\ket{\Psi_0}\)가 기저 상태 \(\ket{\psi_0}\)와 충분한 겹침 \(|c_0|^2\)을 가져야 합니다.
이 점은 오해해서는 안 됩니다. 좋은 초기 상태가 분해능 자체에 대한 요구량(\(n,\tau\))을 줄여 주는 것은 아닙니다. 다만 같은 목표 분해능에서 한 번 실행했을 때 기저 상태가 추출될 확률 \(|c_0|^2\)를 키워, 전체 비용(반복 횟수와 후처리)을 줄여 주는 것입니다. 쉽게 말해 분해능과 성공 확률은 별개의 축이며, 회로 깊이는 분해능을 결정하고 초기 상태 품질은 성공 확률을 결정합니다.
좋은 초기 상태를 얻는 길들
그래서 실제 양자화학에서는 \(\ket{\Psi_0}\)를 가능한 한 \(\ket{\psi_0}\)에 가깝게 만든 뒤 QPE에 넘기는 다양한 전략이 사용됩니다. 대표적인 세 가지를 소개합니다.
변분적 준비.
분자의 화학적 구조에 맞춘 시도 파동함수(ansatz)를 양자 회로로 만들고, 그 회로의 매개변수를 고전 컴퓨터로 최적화해 에너지를 낮추는 방법입니다. 화학에서 잘 알려진 결합 클러스터 이론을 양자 회로 형태로 옮긴 유니터리 결합 클러스터(UCCSD)나, 1차원 강상관 계의 표준 도구인 밀도 행렬 재규격화군(DMRG)을 양자 회로로 구현한 형태 등이 자주 쓰입니다. 이 단계의 목적은 완벽한 답이 아니라, QPE에 넘길 만큼 \(\ket{\psi_0}\)와 충분히 겹치는 상태를 만드는 것입니다.
투영 및 필터링.
해밀토니안의 다항식이나 가우시안 형태의 에너지 필터를 양자 회로로 구현해 원하지 않는 고에너지 성분을 깎아 내는 방법입니다. 임의의 정규화된 연산자를 큰 유니터리 안에 끼워 넣어 양자 회로로 다룰 수 있게 하는 블록 인코딩(block encoding), 그리고 그 위에서 다항식 변환을 정밀히 설계하는 양자 신호 처리(Quantum Signal Processing, QSP)가 이 분야의 표준 도구입니다. 이와 비슷한 정신으로, 허수시간 진화 \(e^{-H\tau}\)를 양자 회로로 흉내 내어 기저 성분의 진폭을 체계적으로 키우는 양자 허수시간 진화(QITE) 기법도 있습니다.
단열적 준비.
풀기 쉬운 시작 해밀토니안의 기저 상태에서 출발해 진짜 해밀토니안으로 천천히 매개변수를 변화시킴으로써, 단열 정리에 의해 자연스럽게 진짜 기저 상태에 가까운 상태로 끌어가는 방법입니다.
맺음말
쇼어 알고리즘에서 QPE로의 흐름은 한 문장으로 요약할 수 있습니다. 쇼어는 \(f(x)=a^x \bmod N\)이 만드는 주기적 중첩의 주기를 QFT로 읽었고, QPE는 \(g(t)=\langle \Psi | U(t) | \Psi \rangle\)가 가지는 진동의 주파수(즉 에너지)를 같은 방식으로 읽습니다. 두 알고리즘은 간섭을 이용해 함수에 숨은 규칙적 위상을 띄워 올린다는 공통 원리를 공유하며, 이 원리가 단 한 번의 측정으로 본질 정보를 다항 자원 안에 압축해 내는 양자 알고리즘의 힘의 원천입니다.
쇼어 알고리즘이 보여 준 양자 우위의 가능성은 분명합니다. 하지만 이를 진짜 큰 분자나 신소재의 에너지 계산에 활용하려면 여전히 갈 길이 남아 있습니다. QPE는 회로 깊이가 깊어 오류 정정 양자 컴퓨터에서야 비로소 제 위력을 발휘하며, 좋은 초기 상태를 얻는 일은 그 자체로 어려운 문제입니다. 그래서 오늘날 연구자들은 QPE 하나에 모든 것을 거는 대신, 변분 알고리즘으로 좋은 초기 상태를 마련하고 단열 준비로 한 단계 더 끌어올린 뒤 QPE의 정밀 분해능으로 마무리하는 모듈형 결합을 적극적으로 시도하고 있습니다. 알고리즘 사이의 우열보다는 시간 진화 구현의 정확도, 초기 상태의 품질, 에너지 스펙트럼 필터의 정교함이라는 세 축을 어떻게 조합하느냐가 미래 양자 알고리즘의 핵심 화두로 떠오르고 있습니다.
이 글에서는 쇼어 알고리즘과 QPE를 양자 알고리즘의 두 큰 줄기로 소개했지만, 분자나 물질의 고유값을 효율적으로 추정하기 위한 양자 알고리즘은 그 밖에도 여러 갈래로 발전해 왔습니다. QPE의 분해능을 유지하면서 회로 깊이를 줄이려는 변형들, 시간 진화 대신 해밀토니안의 다항식이나 적분 변환을 직접 구현하는 새로운 접근들, 노이즈에 강건하도록 고전 최적화와 결합한 하이브리드 방법들이 꾸준히 제안되고 있으며, 저마다 자원 요구량과 정밀도의 균형점이 다릅니다. 기회가 된다면, 다음 글에서는 이러한 양자 고유값 추정 계열 알고리즘들을 차례로 소개하면서, 각 방법이 어떤 상황에서 어떤 장단점을 가지는지 함께 살펴보려 합니다.
더 읽을거리
- 1.P. W. Shor, “Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer,” SIAM Journal on Computing 26, 1484–1509 (1997). 쇼어 알고리즘 원논문.
- 2.M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information, 10th Anniversary Edition, Cambridge University Press (2010). 양자 알고리즘 표준 교과서. 5장(QFT, QPE)과 7장(쇼어 알고리즘) 참조.
- 3.D. S. Abrams and S. Lloyd, “Quantum Algorithm Providing Exponential Speed Increase for Finding Eigenvalues and Eigenvectors,” Physical Review Letters 83, 5162–5165 (1999). QPE를 양자화학(ab initio 물리·화학) 문제에 처음 명시적으로 적용한 논문.
- 4.A. Aspuru-Guzik, A. D. Dutoi, P. J. Love, and M. Head-Gordon, “Simulated Quantum Computation of Molecular Energies,” Science 309, 1704–1707 (2005). 물 분자(HO)와 수소화 리튬(LiH)의 기저 상태 에너지를 양자 위상 추정으로 계산해 보인 양자화학의 대표적인 시연 논문.
- 5.Y. Cao, J. Romero, J. P. Olson, M. Degroote, P. D. Johnson, M. Kieferová, I. D. Kivlichan, T. Menke, B. Peropadre, N. P. D. Sawaya, S. Sim, L. Veis, and A. Aspuru-Guzik, “Quantum Chemistry in the Age of Quantum Computing,” Chemical Reviews 119, 10856–10915 (2019). 양자 컴퓨터를 활용한 양자화학 알고리즘 종합 리뷰.
- 6.김한영, “양자 알고리즘: 소인수 분해 알고리즘”, 고등과학원 HORIZON (2020). https://horizon.kias.re.kr/14195/. 한국어로 쓰인 쇼어 알고리즘 친절한 해설.
- 7.C. Gidney and M. Ekerå, “How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits,” Quantum 5, 433 (2021). arXiv:1905.09749. RSA-2048 소인수분해에 필요한 양자 자원을 구체적으로 추산한 논문.
- 8.R. Babbush, A. Zalcman, C. Gidney, M. Broughton, T. Khattar, H. Neven, T. Bergamaschi, J. Drake, and D. Boneh, “Securing Elliptic Curve Cryptocurrencies against Quantum Vulnerabilities: Resource Estimates and Mitigations,” arXiv:2603.28846 (2026). 256비트 타원곡선 이산 로그 문제에 대한 최신 양자 자원 추산.




관련 논문 보기

 퀀텀웨이브 정기출판물
퀀텀웨이브 정기출판물뉴스레터 구독
파동의교차,지식의융합 양자세계의 최신소식을 받아보세요.
퀀텀웨이브에서 제공하는 콘텐츠

주목할 만한 최신 연구성과
양자물리학 분야의 혁신적 연구 결과를 쉽게 풀어서 소개하고 해설합니다

양자 세부분야 리뷰
양자컴퓨팅, 양자통신, 양자센서 등 각 분야별 심화 리뷰와 동향 분석

국내 연구실 연구 동향
국내 대학 및 연구기관의 양자 관련 연구 소식과 성과를 전해드립니다
주목할 만한 최신 연구
더 많은 내용보기
열린 강의실
대한민국 국방의 중심, 국방과학연구소에서 양자를 만나다.
열린 강의실
국가 표준에서 양자 혁명까지: 한 걸음 더 들어가 본 ‘초전도 양자컴퓨팅 시스템 연구단’

양자 큐레이션
마법 상태 재배: 자원 효율적인 오류 허용 양자컴퓨팅의 구현을 향한 진전
구글 퀀텀 AI(Google Quantum AI) 연구팀이 보편적인 오류 허용 양자 컴퓨팅의 가장 큰 난제였던 '마법 상태(magic state)' 생성 비용을 획기적으로 절감하는 새로운 패러다임, ‘마법 상태 재배(magic state cultivation)’ 기술을 제안했다. 많은 논리적 큐비트 간 상호작용을 필요로 하는 기존의 '마법 상태 증류(magic state distillation)’ 방법과 다르게, 단일 코드 패치 내에서 점진적으로 마법 상태의 신뢰도를 키워 나가는 방식을 사용한다. 그 결과, 마법 상태의 생성 비용이 CNOT 게이트와 비슷한 수준으로 감소하여, 양자 알고리즘의 실질적인 구현에 필요한 자원을 수백에서 수천 배까지 줄일 수 있는 가능성을 열었다. 이는 양자 컴퓨터의 상용화를 향한 중요한 이정표가 될 것이다.